中国传统命理术数是一套建立在规则统计与经验法则之上的知识体系。 随着人工智能推理能力的提升,探索和量化这个具有高度规则性和推演特征的领域成为了可能。
为了进一步探索这一古老而富有生命力的知识体系在智能时代的应用潜力, 我们设计了 Tianfu Agent —— 一个面向专业命理术数研究的 Agentic AI 系统, 通过确定性计算工具、规则化推理经验与生成式叙事能力的融合, 缓解通用大语言模型(LLM)的计算幻觉和逻辑断层问题。
Chinese traditional destiny analysis (Ming Li) is a knowledge system built on rule-based statistics and empirical heuristics. As AI reasoning capabilities advance, it has become possible to explore and quantify this highly rule-governed, deduction-driven domain.
To further explore the potential of this ancient yet vital knowledge system in the age of intelligence, we designed Tianfu Agent — an Agentic AI system for professional destiny analysis research, mitigating the computational hallucinations and logical gaps of general-purpose LLMs through the integration of "deterministic computation tools," "rule-based reasoning experience," and "generative narrative capabilities."
Trimmed Mean Accuracy (截尾均值准确率)
From 2025年第十六屆全球算命師比賽
基于2025 年全球算命师大赛测试, Tianfu Agent 以 50% 的截尾准确率 超越了最先进的通用大模型(最佳基线 40%),接近人类 Top 20 参赛选手的平均水平(53.5%)。
- 考虑到生成式模型的随机性,Tianfu Agent 和所有基线通用模型都进行了 5 轮独立测试并以多数投票结果作为最终答案。
- 截尾均值准确率(Trimmed Mean Accuracy)是比赛官方排名采用的积分方法,去除表现最好和最差的案例后的总分/平均准确率,以排除极端情况的影响。
- 为避免通用模型由训练记忆而非推理得出答案,仅展示了公开语料较少的 2025 年比赛题目。
- 为缓解通用模型计算幻觉,除原始题目外,Prompt中均提供排盘信息。
- 本次比赛共计 3069 个有效参赛者,人类 Top 20 成绩来源于官方统计结果。
- 完整基准测试数据、评测代码见 Mingli-Bench。详细设置可见 Benchmark,Tianfu Agent 的多数选项回答可见详细评估结果。
Based on results from the 2025 Global Fortune Teller Competition, Tianfu Agent achieved a 50% trimmed mean accuracy, surpassing the best general-purpose LLM baseline (40%) and approaching the average level of the human Top 20 contestants (53.5%).
- Given the stochastic nature of generative models, both Tianfu Agent and all baseline LLMs were tested over 5 independent rounds, with majority vote as the final answer.
- Trimmed Mean Accuracy is the official ranking metric of the competition, calculated by removing the best and worst performing cases before averaging, to exclude extreme outliers.
- To prevent LLMs from answering via training memorization rather than reasoning, only 2025 competition questions (with less public corpus exposure) are presented.
- To mitigate computational hallucinations in general-purpose models, pre-computed chart data was provided in the prompt alongside the original questions.
- The competition had 3,069 valid participants; human Top 20 scores are sourced from official statistics.
- Full benchmark data and evaluation code are available at Mingli-Bench. Detailed setup can be found in Benchmark; Tianfu Agent's majority vote answers can be viewed in the detailed results.
重要声明: 本研究为技术探索性原型,仅用于验证 AI 在结构化命理推理中的可行性,命理咨询是开放式对话和个性化诠释,而非选择题,故本结果不代表实际咨询效果。
Important Disclaimer: This research is an exploratory technical prototype, intended solely to validate the feasibility of AI in structured destiny reasoning. Real-world destiny consultation involves open-ended dialogue and personalized interpretation, not multiple-choice questions — these results do not represent actual consultation performance.
专业命理分析面临的困境
命理推理需要从结构化数据(命盘)中进行模式识别,并映射为对人生事件的语义判断。 专业排盘软件已支持将命盘数据序列化为 Prompt 输入,显著降低基础计算错误。 然而,排盘数据预计算 + 通用模型推理的二分法存在结构性限制。
-
衍生数据的组合爆炸。 命理推算往往需要逐级展开大限、流年、飞宫及其观察叠加效果——这些动态衍生数据的组合量随推算深度急剧膨胀,无法穷举后注入 Prompt。
-
空间关系的序列化损失。
能量流通、三方四正、串联等核心规则均依赖一定的空间关系。经过序列化后,这种拓扑信息难以完整保留。 -
推理链的误差累积。 每步都依赖前序步骤的准确结果,早期的微小偏差,会沿推理链逐步放大,这是 LLM 长链推理的通用瓶颈。另外,由于训练语料极度稀缺使模型对领域规则不够熟悉,又缺乏自动化验证手段,导致该问题在命理领域进一步放大。
Tianfu Agent 的设计思路
Agentic 类编码智能体的成功经验表明,当 LLM 被放入一个领域专用的工具环境中——配备文件读写、终端执行、测试反馈——它的能力会远超单纯的文本生成。 Tianfu Agent 尝试沿这一方向,为 LLM 构建命理专用的工具环境,让它能操作命盘对象、调用推算函数、获取计算反馈,而非仅凭训练记忆"背诵"命理知识。 推理链路上,Tianfu Agent 采用渐进式发现策略,由多个 Sub-Agent 各自维护独立的工具集和上下文,逐步展开推理。
本着确定性优先原则,Tianfu Agent 配备超过 200 个专用原子性工具, 完成包括排盘、时间推演、空间路径等可精确计算的方法。 然而,确定性计算能覆盖的范围终究有限—— 当面对繁杂的工具输出、规则约束、解读片段, 由于缺乏自动化验证手段,命理领域中确定性的边界究竟在哪里? 为此,Tianfu Agent 试图从工具调度、规则封装与信心度量三个角度增强推理链路。
下面通过几个真实案例,直观展示这些策略在实际推理中的运作方式:
计算型工具的划分与调用
通用 Agent 产品仅用少量通用工具即可覆盖多数场景。命理领域则不然:不同流派各有一套专用推算方法,工具种类繁杂且存在跨流派冲突。全部堆叠会导致模型的工具选择准确率下降,过度精简又丧失专业深度。我们按程度将工具划分为四类,来平衡工具精度与上下文负担:
| 类型 | LLM 可理解性 | 可穷举性 | 描述 | 示例 |
|---|---|---|---|---|
| 自动注入型 | ✓ | ✓ | 零歧义概念,无需模型介入 | 十神、星耀、宫位 |
| 按需调用型 | ✓ | ✗ | 模型可直接推理并自行判断调用参数 | 生克、飞宫 |
| 转译调用型 | ✗ | ✓ | 需通过预设翻译转换工具名称后调用,避免模型幻觉 | 在天呈象转在地成型、法象 |
| 触发注入型 | ✗ | ✗ | 仅特定 Sub Agent 可调用,配有专用推理知识库和校验方法 | 北派用神 |
推理也被视为一种工具
在代码等通用领域,模型自身的推理能力足以支撑复杂的流程控制与决策。 但在命理领域,缺乏足够强大的领域模型意味着我们无法将推理直接交给模型, 而若将规则写入 System Prompt 或 Few-shot 示例, 本质上是依赖模型"记住并遵循",在规则数量多、条件复杂时,会出现选择性忽略和推理路径不可控等问题。
为此,除计算工具外,Tianfu Agent 将复杂推理规则也视为一种可调用工具: 人类专家预先为每条规则标注适用场景和优先级元数据(时间跨度、事件类型、适用条件等), 每条规则被封装为独立函数(内部结合LLM调用), 接受命盘状态输入,返回结论与置信度。 确保仅在需要时注入上下文,避免大量抽象规则造成的上下文污染。
以置信度量化应对不可验证性
由于无法提供自动化验证机制,推理过程的稳定性显得尤为重要,为此我们将不确定性量化(Uncertainty Quantification)融入推理的各个阶段, 用以模拟人类专家的隐式直觉,该信心度量将在更高层的推理中作为采纳标准,大致分为以下几种:
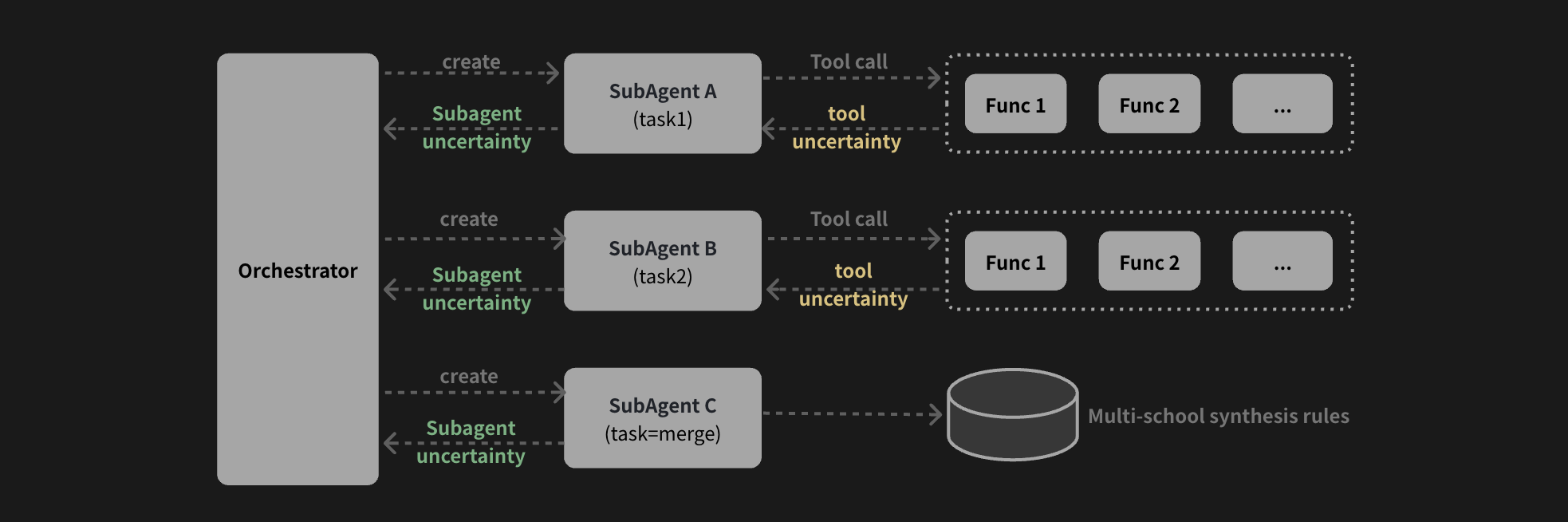
不确定性量化示意图
- 工具输出的不确定性,面向
强弱判断、多象吉凶等非确定性计算/规则推理工具,由内置工具根据算法提供; - Sub-Agent 的不确定性,由LLM自评估判断当前结论的显著性,主要面向单一理论体系下推理过程的评估;
- 多流派合参的不确定性,用于调和流派间结论矛盾,并综合得出面向用户的最终回答。
The Challenge of Professional Destiny Analysis
Destiny reasoning requires pattern recognition from structured data (natal charts) and mapping those patterns to semantic judgments about life events. Professional charting software can serialize chart data as prompt input, significantly reducing basic computational errors. However, the dichotomy of pre-computed chart data + general-purpose model reasoning has structural limitations.
-
Combinatorial explosion of derived data. Destiny calculation often requires progressively expanding major periods (Da Xian), annual periods (Liu Nian), Flying Palace transformations, and their superimposed effects — the combinatorial volume of these dynamically derived data explodes with reasoning depth, making exhaustive prompt injection infeasible.
-
Serialization loss of spatial relationships. Core rules such as "energy flow," "Three Harmonies and Four Cardinals" (San Fang Si Zheng), and "serial linkage" all depend on spatial relationships. After serialization, such topological information is difficult to preserve intact.
-
Error accumulation in reasoning chains. Each step depends on the accuracy of prior steps; small early deviations propagate and amplify along the reasoning chain — a well-known bottleneck of LLM long-chain reasoning. Furthermore, extremely scarce training corpora leave models unfamiliar with domain rules, and the lack of automated verification further exacerbates this problem in the destiny analysis domain.
Design Approach of Tianfu Agent
The success of agentic coding tools has shown that when an LLM is placed in a domain-specific tool environment — equipped with file I/O, terminal execution, and test feedback — its capabilities far exceed pure text generation. Tianfu Agent follows this direction: building a destiny-analysis-specific tool environment for the LLM, enabling it to manipulate chart objects, invoke calculation functions, and receive computational feedback, rather than merely "reciting" destiny knowledge from training memory. On the reasoning pipeline, Tianfu Agent employs a progressive discovery strategy, with multiple Sub-Agents each maintaining independent tool sets and contexts, incrementally expanding the reasoning process.
Guided by a determinism-first principle, Tianfu Agent is equipped with over 200 specialized atomic tools for precisely computable operations including chart casting, temporal derivation, and spatial path traversal. However, the scope that deterministic computation can cover is ultimately limited — when facing complex tool outputs, rule constraints, and interpretation fragments, and lacking automated verification methods, where exactly is the boundary of "determinism" in the destiny analysis domain? To address this, Tianfu Agent attempts to strengthen the reasoning pipeline from three angles: tool orchestration, rule encapsulation, and confidence quantification.
The following real-world cases illustrate how these strategies operate in practice:
Tool Classification and Invocation
Mainstream agent products cover most scenarios with just a small set of general-purpose tools. The destiny analysis domain is different: different schools each have their own specialized calculation methods, with diverse tool types and cross-school conflicts. Stacking all tools degrades the model's tool selection accuracy; over-simplification sacrifices professional depth. We classify tools into four categories to balance tool precision and context burden:
| Type | LLM Comprehensibility | Exhaustibility | Description | Example |
|---|---|---|---|---|
| Auto-injected | ✓ | ✓ | Zero-ambiguity concepts requiring no model involvement | Ten Gods, stars, palaces |
| On-demand invocation | ✓ | ✗ | Model directly reasons and determines invocation parameters | Sheng Ke, Fei Gong |
| Translation-wrapped | ✗ | ✓ | Invoked after preset translation converts tool names to prevent hallucinations | Zai Tian Cheng Xiang, Fa Xiang |
| Trigger-injected | ✗ | ✗ | Only invocable by specific Sub-Agents with dedicated knowledge bases and validation | Northern School Yong Shen analysis |
Reasoning as a Callable Tool
In general domains like code, the model's own reasoning capabilities suffice for complex flow control and decision-making. In destiny analysis, however, the lack of a sufficiently powerful domain model means reasoning cannot be directly delegated to the model. Writing rules into System Prompts or few-shot examples essentially relies on the model to "remember and follow" — when rules are numerous and conditions complex, selective omission and uncontrollable reasoning paths emerge. To address this, beyond computation tools, Tianfu Agent treats complex reasoning rules as callable tools: each rule is encapsulated as an independent function (internally combining LLM calls as needed), accepting chart state input and returning conclusions with confidence scores. Human experts pre-annotate each rule with applicable scenario and priority metadata (time span, event type, applicable conditions, etc.), and rules are injected into context only when needed, preventing large volumes of abstract interpretation rules from causing context pollution.
Addressing Unverifiability with Confidence Quantification
Given the absence of automated verification mechanisms, reasoning stability becomes paramount. We embed uncertainty quantification into every phase of reasoning, simulating the "implicit intuition" of human experts. This "confidence measure" serves as an adoption criterion in higher-level reasoning, roughly categorized as follows:
Uncertainty Quantification Diagram
- Tool output uncertainty — for non-deterministic computation/rule reasoning tools such as "strength assessment" and "multi-image auspiciousness"; provided by built-in tool algorithms.
- Sub-Agent uncertainty — LLM self-assesses the significance of current conclusions, addressing uncertainty within a single theoretical framework.
- Multi-school synthesis uncertainty — for reconciling contradictions between schools' conclusions and producing the final user-facing answer.
局限性与未来展望
本评测存在明确的边界。例如,样本量有限,不足以验证跨年份、地域、题型的泛化能力。 另外,本评测采用选择题形式,衡量封闭域推理和选项辨析能力, 缺乏对开放式对话场景,例如追问、表达方式、情绪处理和个性化解释等能力的评估。
Tianfu Agent 的设计与实现为了在 LLMs 及相关技术快速发展的当下,探索中国传统命理领域的自动化推理潜力, 未来,如何实现更加智能的命理学推理,依然充满了未知和挑战。 随着AI技术的持续提升,我们也将在此基础上继续探索传统命理自动化推理更多可能性。
Limitations and Outlook
This evaluation has clear boundaries. For instance, the limited sample size is insufficient for verifying generalization across years, regions, and question types. Additionally, the multiple-choice format measures closed-domain reasoning and option discrimination, but lacks evaluation of open-ended dialogue capabilities such as follow-up questioning, expression style, emotional handling, and personalized interpretation.
Tianfu Agent was designed and implemented to explore the potential of automated reasoning in Chinese traditional destiny analysis amid the rapid advancement of LLMs and related technologies. How to achieve more intelligent destiny reasoning in the future remains full of unknowns and challenges. As AI technology continues to advance, we will continue to explore further possibilities in automated reasoning for traditional destiny analysis.
Benchmark 详情
| 截尾均值准确率 | 截尾分数 | 整体准确率 | 整体分数 | |
|---|---|---|---|---|
| Human | ||||
| 参赛者 Top-20 avg | 53.5% | 16 | 51.88% | 20.75 |
| Agent | ||||
| Tianfu Agent | 50.0% | 15 | 45.0% | 18.0 |
| LLMs | ||||
| Claude Opus 4.6 | 40.0% | 12 | 37.5% | 15.0 |
| Doubao Seed 2.0 Pro | 36.7% | 11 | 37.5% | 15.0 |
| Gemini 3.1 Pro Preview | 36.7% | 11 | 37.5% | 15.0 |
| Grok-4.2 | 36.7% | 11 | 35.0% | 14.0 |
| GPT-5.4 | 30.0% | 9 | 32.5% | 13.0 |
| MiniMax M2.7 | 30.0% | 9 | 30.0% | 12.0 |
| DeepSeek V3.2 | 26.7% | 8 | 30.0% | 12.0 |
| Kimi K2.5 | 26.7% | 8 | 27.5% | 11.0 |
| Qwen3.6 Plus | 23.3% | 7 | 27.5% | 11.0 |
- 数据集:
- 来源于2025年第十六届全球算命师比赛官方题库,选择题格式(A/B/C/D),具有客观可验证的标准答案。
- 在此之前,BaziQA(Chen et al., 2025)已基于该赛事题库(2021–2025年)构建了针对八字领域的标准化基准。
- 测试集包含 8 个案例共 40 道题,涵盖性格、事业、婚姻、健康等维度。
- 参赛选手代表的是本次比赛参与者水平,不代表人类命理师的顶尖水平。
- 基线模型设置:
- 每个模型进行 5 轮独立测试,采用 Majority Vote 策略,每道题在至少 3 轮中答对才计为通过。LLM 仍可能因采样、MOE等差异产生不同输出。
- 已提供预计算的八字和紫微命盘数据(使用 iztro API 生成),Temperature: 0.0。
- 系统提示词和命盘数据格式见
mingli_bench/models/base.py。
- Tianfu Agent 设置:
- 使用排盘工具实时计算和 multi-Agent 协作推理。
- 为确保公平性,关闭了"主动询问"、"网络检索"、"奇门遁甲"等工具调用。
- 设计基于主流命理学理论和 Agent 设计原则,未使用任何赛事题目进行架构优化或参数调优。
- 指标说明:
- 整体准确率: 5轮测试中题目在至少3轮中答对才计为通过。
- 截尾均值准确率(Trimmed Mean Accuracy): 比赛官方排名积分方法,去除表现最好和最差的案例后计算。
- 参赛者 Top-20 Avg: 排名前20的参赛选手平均成绩。
- 完整数据集、评测代码见 Mingli-Bench。
- 题目数据集:
mingli_bench/data/data.json— 160道标准化题目(2022-2025年) - 命盘数据:
mingli_bench/data/data_with_astro.json— 预计算的八字和紫微命盘
- 题目数据集:
Benchmark Details
| Trimmed Mean Accuracy | Trimmed Score | Overall Accuracy | Overall Score | |
|---|---|---|---|---|
| Human | ||||
| Top-20 Contestants avg | 53.5% | 16 | 51.88% | 20.75 |
| Agent | ||||
| Tianfu Agent | 50.0% | 15 | 45.0% | 18.0 |
| LLMs | ||||
| Claude Opus 4.6 | 40.0% | 12 | 37.5% | 15.0 |
| Doubao Seed 2.0 Pro | 36.7% | 11 | 37.5% | 15.0 |
| Gemini 3.1 Pro Preview | 36.7% | 11 | 37.5% | 15.0 |
| Grok-4.2 | 36.7% | 11 | 35.0% | 14.0 |
| GPT-5.4 | 30.0% | 9 | 32.5% | 13.0 |
| MiniMax M2.7 | 30.0% | 9 | 30.0% | 12.0 |
| DeepSeek V3.2 | 26.7% | 8 | 30.0% | 12.0 |
| Kimi K2.5 | 26.7% | 8 | 27.5% | 11.0 |
| Qwen3.6 Plus | 23.3% | 7 | 27.5% | 11.0 |
- Dataset:
- Sourced from the 2025 16th Global Fortune Teller Competition official question bank. Multiple-choice format (A/B/C/D) based on real-life events with objectively verifiable ground-truth answers.
- Prior to this work, BaziQA (Chen et al., 2025) established a standardized benchmark from the same competition series (2021–2025). - The test set contains 8 cases with 40 questions covering personality, career, marriage, and health.
- Contestants represent the level of this competition's participants, not the peak level of human destiny practitioners.
- Baseline Models:
- Each model was tested over 5 independent rounds using Majority Vote; a question counts as correct only if answered correctly in at least 3 rounds. Despite setting temperature=0.0, LLMs may still produce different outputs due to sampling, MoE, and other mechanisms.
- Pre-computed Ba Zi and Zi Wei Dou Shu chart data provided (generated via the iztro API). Temperature: 0.0, Max Tokens: 8192.
- System prompt and chart data format:
MingLi-Bench/models/base.py.
- Tianfu Agent:
- Uses chart-casting tools for real-time computation and multi-Agent collaborative reasoning.
- To ensure evaluation fairness, "proactive questioning," "web search," and "Qi Men Dun Jia" tool calls were disabled.
- Design based on mainstream destiny analysis theories and general Agent design principles; no competition questions were used for architecture optimization or parameter tuning.
- Metric Definitions:
- Overall Accuracy: A question counts as correct only if answered correctly in at least 3 of 5 rounds.
- Trimmed Mean Accuracy: Official competition ranking metric; removes each model's best and worst performing cases before computing accuracy.
- Top-20 Contestants Avg: Average scores of the Top 20 contestants in the 2025 competition.
- Full dataset and evaluation code at Mingli-Bench.
- Question dataset:
data/data.json— 160 standardized questions (2022-2025) - Chart data:
data/data_with_astro.json— Pre-computed Ba Zi and Zi Wei charts
- Question dataset:
Tianfu Agent 详细评估结果
| 题号 | 原题目 | 正确选项 | 结果 | 评估链接 |
|---|---|---|---|---|
| 1 | 此命出生家境如何? | B | C | 推理1 |
| 2 | 婚姻如何? | D | D | 推理2 |
| 3 | 此人年青時何種工作? | B | B | 推理3 |
| 4 | 1980 年發生何事? | A | A | 推理4 |
| 5 | 1993 年發生何事? | B | A | 推理5 |
| 6 | 2022 年至現在,命主的健康狀况如何? | D | D | 推理6 |
| 7 | 命主的性格特質、學歷水平和現時職業情况如何? | B | D | 推理7 |
| 8 | 命主在 2018 至現在,財政狀態和事業運勢怎樣? | D | C | 推理8 |
| 9 | 命主現時的婚姻狀况如何? | D | B | 推理9 |
| 10 | 現時命主與父母的關係、家庭背景? | B | B | 推理10 |
| 11 | 命主出身及家庭情况? | B | C | 推理11 |
| 12 | 命主的样貌、性情、爱好及职业? | B | C | 推理12 |
| 13 | 命主的学历和职业状况? | D | B | 推理13 |
| 14 | 命主的婚恋和子女情况? | C | A | 推理14 |
| 15 | 2022年,命主发生的重要事件? | A | C | 推理15 |
| 16 | 命主儿时家庭情况? | C | C | 推理16 |
| 17 | 命主 2001 年发生何事? | D | C | 推理17 |
| 18 | 命主2022年后的职业行业情况? | B | D | 推理18 |
| 19 | 命主感情状况为何? | A | A | 推理19 |
| 20 | 命主抑郁症状最严重的年份? | B | C | 推理20 |
| 21 | 命主目前的工作和生活情况如何? | D | D | 推理21 |
| 22 | 命主在 2004时发生了什么事? | A | D | 推理22 |
| 23 | 命主在哪一年结婚的? | D | D | 推理23 |
| 24 | 命主现在的婚姻状况,子女状况如何? | A | B | 推理24 |
| 25 | 命主个性及特色如何? | B | B | 推理25 |
| 26 | 命主的性格和出生如何? | A | A | 推理26 |
| 27 | 命主喜欢的居家装修风格是? | B | B | 推理27 |
| 28 | 在丙辰大限(43-52),命主在哪一年出国创业?和什么领域相关? | B | B | 推理28 |
| 29 | 命主在 2021 年,发生何事? | D | A | 推理29 |
| 30 | 命主在 2024 年的健康状况如何? | C | B | 推理30 |
| 31 | 命主原生家庭父母親狀况? | A | B | 推理31 |
| 32 | 命主大學時期讀什麼科系? | C | B | 推理32 |
| 33 | 命主目前的婚姻狀態? | B | B | 推理33 |
| 34 | 命主現職行業? | D | A | 推理34 |
| 35 | 對命主之描述? | B | B | 推理35 |
| 36 | 命主學歷狀况為何? | C | C | 推理36 |
| 37 | 命主出社會後的工作? | A | A | 推理37 |
| 38 | 命主早年一直在北京生活,直到哪個歲運有搬遷大變動? | D | A | 推理38 |
| 39 | 命主身體狀況為何? | C | B | 推理39 |
| 40 | 命主一生整體外界評價的性格如何? | A | A | 推理40 |
Tianfu Agent Detailed Evaluation Results
| Question | Original Question | Correct Answer | Majority Vote | Evaluation Link |
|---|---|---|---|---|
| 1 | 此命出生家境如何? | B | C | Reasoning 1 |
| 2 | 婚姻如何? | D | D | Reasoning 2 |
| 3 | 此人年青時何種工作? | B | B | Reasoning 3 |
| 4 | 1980 年發生何事? | A | A | Reasoning 4 |
| 5 | 1993 年發生何事? | B | A | Reasoning 5 |
| 6 | 2022 年至現在,命主的健康狀况如何? | D | D | Reasoning 6 |
| 7 | 命主的性格特質、學歷水平和現時職業情况如何? | B | D | Reasoning 7 |
| 8 | 命主在 2018 至現在,財政狀態和事業運勢怎樣? | D | C | Reasoning 8 |
| 9 | 命主現時的婚姻狀况如何? | D | B | Reasoning 9 |
| 10 | 現時命主與父母的關係、家庭背景? | B | B | Reasoning 10 |
| 11 | 命主出身及家庭情况? | B | C | Reasoning 11 |
| 12 | 命主的样貌、性情、爱好及职业? | B | C | Reasoning 12 |
| 13 | 命主的学历和职业状况? | D | B | Reasoning 13 |
| 14 | 命主的婚恋和子女情况? | C | A | Reasoning 14 |
| 15 | 2022年,命主发生的重要事件? | A | C | Reasoning 15 |
| 16 | 命主儿时家庭情况? | C | C | Reasoning 16 |
| 17 | 命主 2001 年发生何事? | D | C | Reasoning 17 |
| 18 | 命主2022年后的职业行业情况? | B | D | Reasoning 18 |
| 19 | 命主感情状况为何? | A | A | Reasoning 19 |
| 20 | 命主抑郁症状最严重的年份? | B | C | Reasoning 20 |
| 21 | 命主目前的工作和生活情况如何? | D | D | Reasoning 21 |
| 22 | 命主在 2004时发生了什么事? | A | D | Reasoning 22 |
| 23 | 命主在哪一年结婚的? | D | D | Reasoning 23 |
| 24 | 命主现在的婚姻状况,子女状况如何? | A | B | Reasoning 24 |
| 25 | 命主个性及特色如何? | B | B | Reasoning 25 |
| 26 | 命主的性格和出生如何? | A | A | Reasoning 26 |
| 27 | 命主喜欢的居家装修风格是? | B | B | Reasoning 27 |
| 28 | 在丙辰大限(43-52),命主在哪一年出国创业?和什么领域相关? | B | B | Reasoning 28 |
| 29 | 命主在 2021 年,发生何事? | D | A | Reasoning 29 |
| 30 | 命主在 2024 年的健康状况如何? | C | B | Reasoning 30 |
| 31 | 命主原生家庭父母親狀况? | A | B | Reasoning 31 |
| 32 | 命主大學時期讀什麼科系? | C | B | Reasoning 32 |
| 33 | 命主目前的婚姻狀態? | B | B | Reasoning 33 |
| 34 | 命主現職行業? | D | A | Reasoning 34 |
| 35 | 對命主之描述? | B | B | Reasoning 35 |
| 36 | 命主學歷狀况為何? | C | C | Reasoning 36 |
| 37 | 命主出社會後的工作? | A | A | Reasoning 37 |
| 38 | 命主早年一直在北京生活,直到哪個歲運有搬遷大變動? | D | A | Reasoning 38 |
| 39 | 命主身體狀況為何? | C | B | Reasoning 39 |
| 40 | 命主一生整體外界評價的性格如何? | A | A | Reasoning 40 |